

� LIMITED PREVIEW
This product is currently in limited preview. Features and functionality may change.
Overview
NikaETL is a powerful data processing engineering platform that enables you to deploy Python scripts as serverless functions with one click, and leverage AI agents to create intelligent flow diagrams for complex data processing pipelines. Built for data engineers and analysts who need scalable, automated ETL workflows.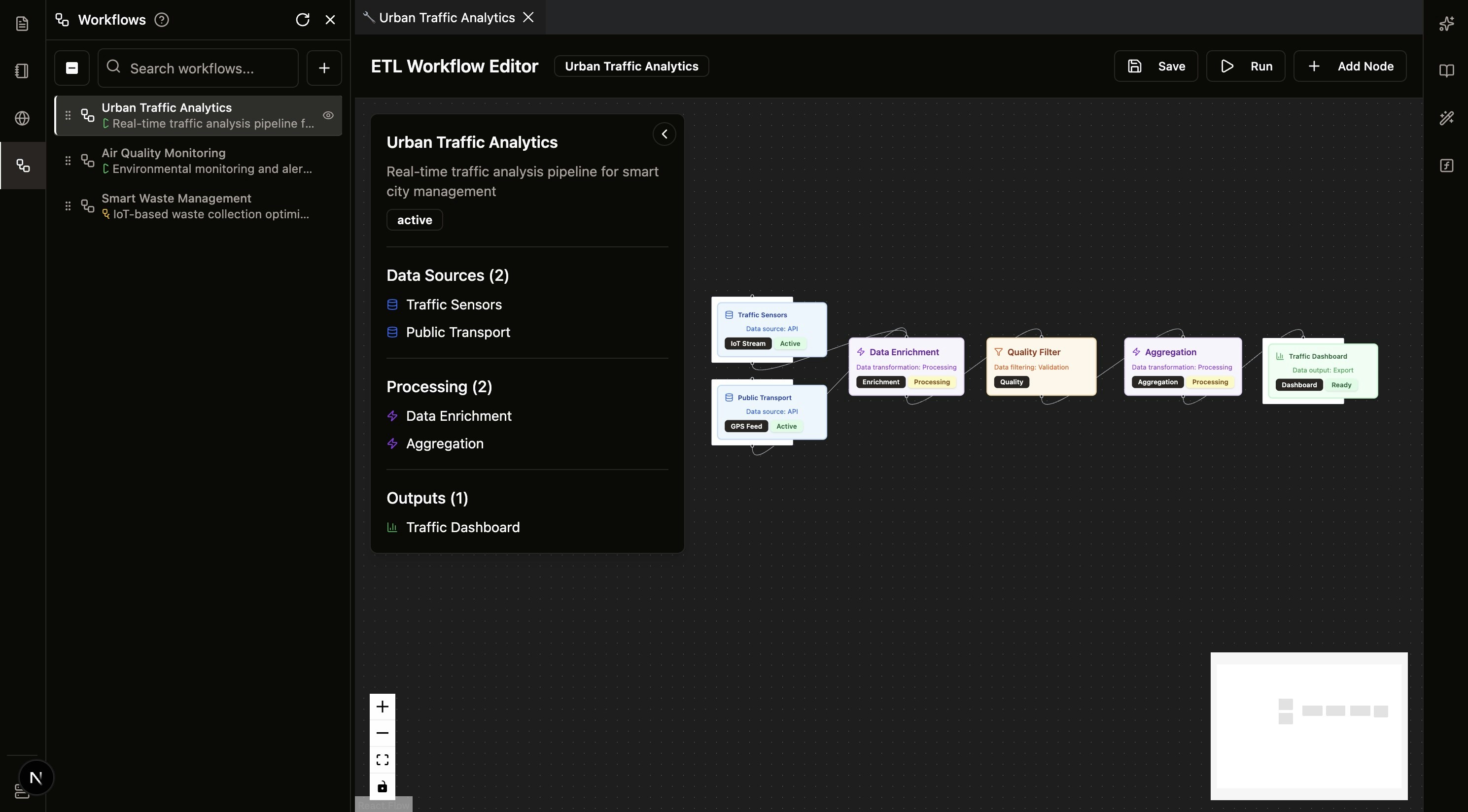
Key Features
One-Click Serverless Deployment
- Instant Deployment: Deploy Python scripts as serverless functions with a single click
- Auto-Scaling: Automatic scaling based on workload demands
- Pay-Per-Use: Only pay for actual function execution time
- Zero Infrastructure: No server management or configuration required
AI-Powered Flow Design
- Intelligent Flow Creation: AI agent automatically creates optimal flow diagrams
- Smart Function Chaining: AI suggests the best way to connect functions
- Performance Optimization: AI recommends optimizations for data processing
- Error Handling: AI-generated error handling and recovery mechanisms
Data Processing Engineering
- ETL Workflows: Extract, Transform, Load data processing pipelines
- Data Validation: Built-in data quality checks and validation
- Transformation Tools: Rich library of data transformation functions
- Monitoring: Real-time monitoring and alerting for data pipelines
Integration Capabilities
- Multiple Data Sources: Connect to databases, APIs, cloud storage, and more
- Format Support: Handle CSV, JSON, Parquet, Avro, and other formats
- Geospatial Data: Specialized support for spatial data processing
- Real-time Processing: Stream processing capabilities for live data
Getting Started
Deploying Your First Function
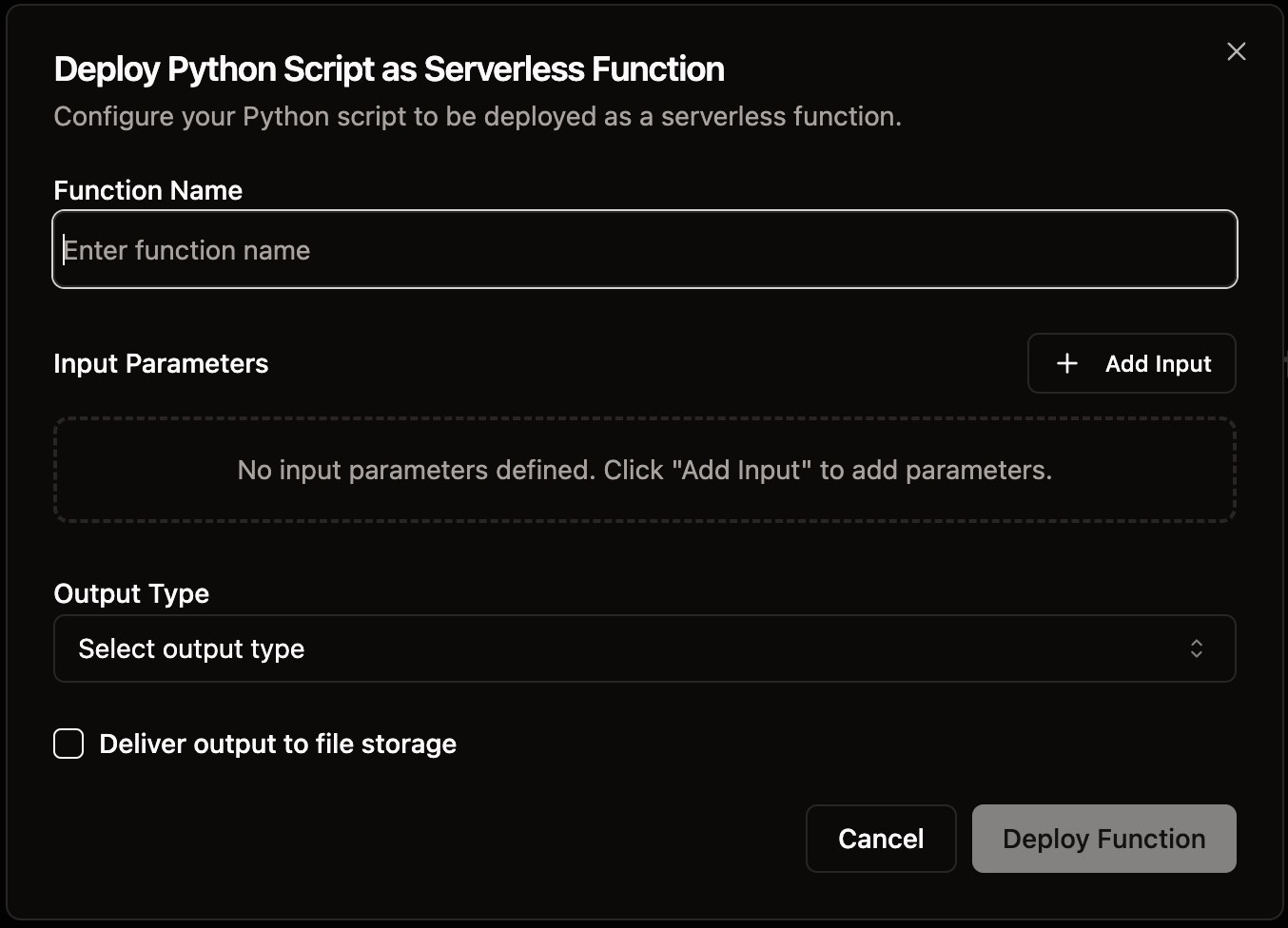
Best Practices
Function Design
- Single Responsibility: Each function should do one thing well
- Error Handling: Implement comprehensive error handling
- Logging: Add detailed logging for debugging
- Testing: Test functions thoroughly before deployment
Flow Design
- Modularity: Break complex workflows into smaller functions
- Error Recovery: Implement retry and recovery mechanisms
- Monitoring: Add comprehensive monitoring and alerting
- Documentation: Document flow logic and dependencies
Performance
- Optimization: Use AI suggestions for performance optimization
- Caching: Implement caching for frequently accessed data
- Parallelization: Use parallel processing where possible
- Resource Management: Monitor and optimize resource usage
Get Expert Help
Talk to a Geospatial Expert
Need help with your geospatial projects? Our team of experts is here to assist you with implementation, best practices, and technical support.
Other ways to get help:
- Guides: Use the /guides tab for detailed tutorials
- Community: Ask questions in our community forum
- Support: Send us a support request